From past few days I have been dwelling in android to make a utility, an application that I can be used when I am reading and article or when I am researching about something.
The premise lies around on the fact that the application itself doesn’t have a screen but what it plays around is on background activity. So it silently keeps on running and when an interrupt comes it performs an action.
Since I am not very well versed with how to make an android of such kind, I searched and found out about the component which does this and it’s called a Service. This is very similar to the concept of linux services or daemons.
The application I am designing is basically a combination of overlay activity and background services. Hence I wouldn’t say that there will be no user interaction at all but it will be really minimal and user doesn’t have a inherent knowledge about the service.
So it was time to do some more reading on android services.
A
DocumentationServiceis an application component that can perform long-running operations in the background, and it doesn’t provide a user interface. Another application component can start a service, and it continues to run in the background even if the user switches to another application.
This was something that I really wanted, now there are a few caveats to this blogpost that is my understanding and knowledge about android application development. So I would tell you take things with a pinch of salt and let me know if there is anything wrong with my understanding.
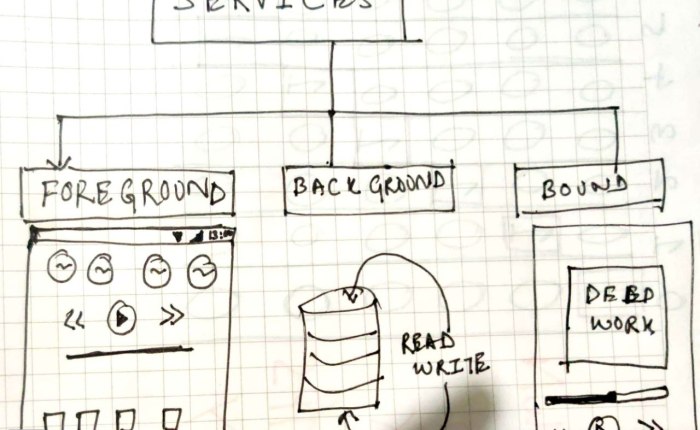
When I read more about services I got to know there are 3 kinds of them:
Foreground
This is how you see spotify music work, even when the application is not in the display you can change songs through notification and there is one level of user interaction involved with this.
Background
Services with which user don’t want to know about or interact, like updating a database, fetching some resources etc.
Bound
Bound services are the one which are attach to the user activity, the quickest example I can give is music player, you don’t want the music to stop when you switch application and in the mean time you want to control the music when you switch back to the application.
Mostly people use services so that all the heavy lifting is done in the background. I had a unique case what I wanted is a service that keeps running and observing, when something is changed or when it is poked then react to it.
If you have seen the design of facebook messenger, the chat heads comes to life only when you have a message, this was somewhat the use case.
The biggest thing that I learnt is android doesn’t allow you run a background service without notifying the user. This is a new addition the happened after Android Oreo.
Implementation
There are two kinds of implementation that android provides,
The former as it’s name suggest is used to spawn service and is attached to the main thread. While IntentSrvice is something more peculiar where you can divide the work and do it without actually make your application wait for something. For example suppose you are playing a game and you are in middle of level 1, now an IntentService can be used to spawn to download and keep all the data required for level 2 without affecting your game play.
Another amazing thing about services is that, it is a singleton, that means however time you are going to start a service, you are not going to interact with too many objects, it’s the same class which you are going to talk to.
Conclusion
These are few of the learning that I got about services in android, I didn’t put much code here because most of them is available in the references. I enjoyed my time learning about how services are designed and how they are manged internally in android. Let me know what you think about it.
Till then, Keep Hacking!
References:
https://www.hellsoft.se/how-to-service-on-android—part-2/
https://proandroiddev.com/deep-dive-into-android-services-4830b8c9a09
https://robertohuertas.com/2019/06/29/android_foreground_services/
https://medium.com/@harunwangereka/android-background-services-b5aac6be3f04