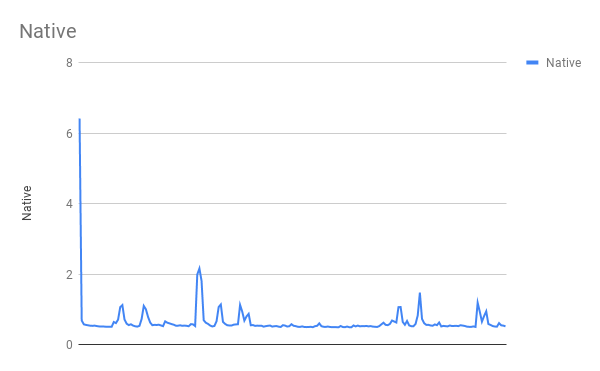
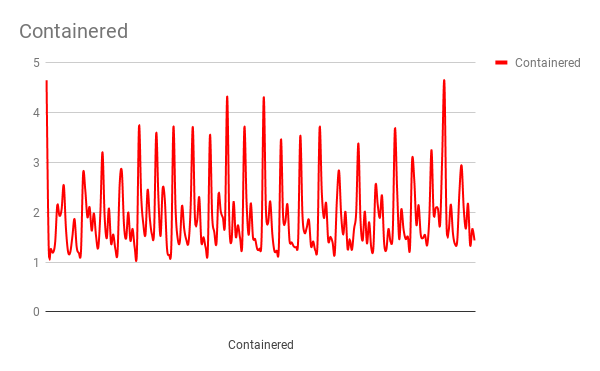
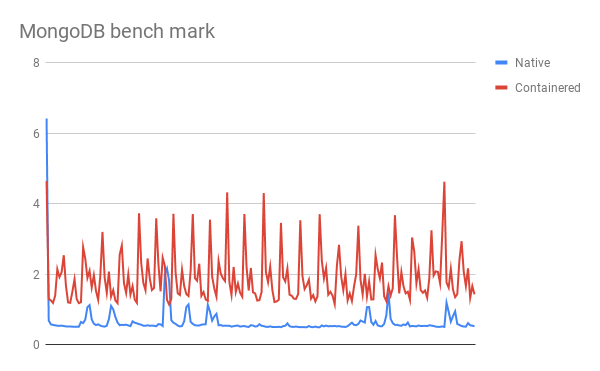
I have been working on a pet project to write a File Indexer, which is a utility that helps me to search a directory for a given word or phrase.
The motivation behind to build this utility was so that we could search the chat log files for dgplug. We have a lot of online classes and guest sessions and at times, we just remember the name or a phrase used in the class, backtracking the files using these phrases aren’t possible as of now. I thought I will give a stab at this issue and since I am trying to learn golang I used it to implement my solution. It took me a span of two weeks where I spent time to upskill certain aspects and also to come up with a clean solution.
Exploration
This started with me exploring similar solutions, because why not? It is always better to improve an existing solution than to write your own. I didn’t find any which suited our need though so I ended up writing my own. The exploration led me to discover a few libraries that proved useful. I found fulltext and Bleve.
I found bleve to have better documentation and some really beautiful thought behind the library. Really minimal yet effective. At the end of it all, I was sure I was going to use it.
Working On the Solution
After all the exploration I tried to break the problem into smaller pieces and then go about solving each one of them. So the first one was to understand how bleve worked. I found out that bleve creates an index first; for which we need to give it the list of files. The index is basically a map structure behind the scenes, where you give it the id and content to be indexed. So what could be a unique constraint for a file in a filesystem? The path of the file! I used it as the id to my structure and the content of my file as the value.
After figuring this out, I wrote a function which takes the directory as the argument and gives back the path of each file as well as its contents. After a few iterative. improvements it diverged into two functions; one responsible to get the path of all the files and the other to just read the file and get the content out.
func fileNameContentMap() []FileIndexer {
var ROOTPATH = config.RootDirectory
var files []string
var filesIndex FileIndexer
var fileIndexer []FileIndexer
err := filepath.Walk(ROOTPATH, func(path string, info os.FileInfo, err error) error {
if !info.IsDir() {
files = append(files, path)
}
return nil
})
checkerr(err)
for _, filename := range files {
content := getContent(filename)
filesIndex = FileIndexer{Filename: filename, FileContent: content}
fileIndexer = append(fileIndexer, filesIndex)
}
return fileIndexer
}
This forms a struct which stores the name of the file and the content of the file. And since I can have many files I need to have a array of said struct. This is how a simple data structure evolves into a complex one.
Now I have the utility of getting all files, getting content of the file and making an index.
This leads us to the next crucial step.
How Do I Search?
Now that I’ve prepped my data the next logical step was to retrieve the searched results. The way we search something is by passing a query so I duck-typed a function which accepts a string and then went on a spree of documentation look up to find out how do I search in bleve. I found a simple implementation which returns the id of the file which is the path and match score.
func searchResults(indexFilename string, searchWord string) *bleve.SearchResult {
index, _ := bleve.Open(indexFilename)
defer index.Close()
query := bleve.NewQueryStringQuery(searchWord)
searchRequest := bleve.NewSearchRequest(query)
searchResult, _ := index.Search(searchRequest)
return searchResult
}
This function opens the index and search for the term and returns back the information.
Let’s Serve It
After all that is done I need to have a service which does this on demand so I wrote a simple API server which has two endpoints index and search. The way mux works is you give the endpoint to the handler and the function to be mapped with it. I had to restructure the code in order to make this work. I faced a really crazy bug which when I narrowed it down, came to a point of a memory leak and yes, it was because I left the file read stream open, so remember when you Open always defer Close.
I used Postman to heavily test it and it was returning good responses. A dummy response looks like this:
[{"index":"irclogs.bleve","id":"logs/some/hey.txt","score":0.6912244671221862,"sort":["_score"]}]
Missing Parts?
The missing part was I didn’t use any dependency manager which Kushal pointed out to me, so I landed up using dep to do this for me. The next one was one of my favourite problems of the project and that was how to auto-index a file. Suppose my service is running and I added one more file to the directory, then this file’s content wouldn’t come up in the search because the indexer hasn’t run on it yet. This was a fascinating problem and I tried to approach it from many different angles. First I thought I would re-run the service every time I add a file but that’s not a graceful solution. Then I thought I would write a cron job which would ping /index at regular intervals and yet again that struck me as inelegant. Finally I wondered if I could detect changes in a file. This led me to explore gin, modd and fresh.
Gin was not very compatible with mux so didn’t use it, modd was really nice but I needed to kill the server to restart it since two services cannot run on a single port and every time I kill that service I kill the modd daemon too so that possibility also got ruled out.
Finally the best solution was fresh although I had to write a custom config file to suit the requirement, this approach still has issues with nested repository indexing which I am thinking how to figure out.
What’s Next?
This project is yet to be containerised and there are missing test cases so I would be working on them, as and when I get time.
I have learnt a lot of new things about the filesystem and how it works, because of this project. This little project also helped me appreciate a lot of golang concepts and made me realise the power of static typing.
If you are interested you are welcome to contribute to file-indexer. Feel free to ping me.
Till then, Happy Hacking!